I've been talking about QA and test automation but haven't really gone into much detail about what exactly I want to do. Hopefully, I've made a sufficiently strong case for a task automation system vs. a strict test automation system already but I'm open to other thoughts. Please keep in mind that most of this is really early and there are still parts which still need to be planned out.
If you think that all of this sounds a lot like AutoQA, you'd be right. From this high level overview, a lot of this does describe AutoQA - the major differences are in the details of task execution and how tightly coupled all the compoents are to eachother and to parts of the Fedora infrastructure.
Overview
The basic idea is modeled somewhat after continuous integration systems where a scheduler listens for signals from fedmsg and schedules tasks based on the content of those messages.
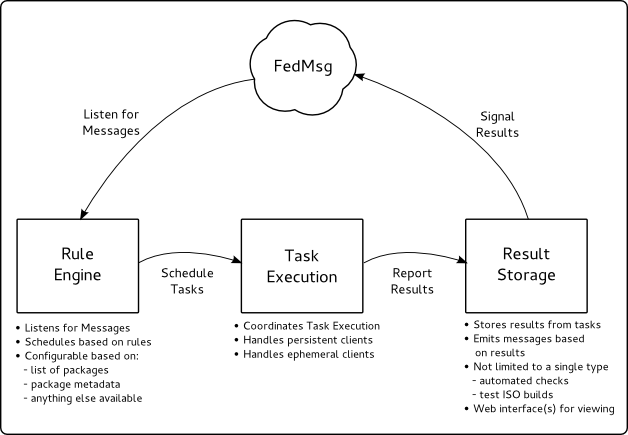
Looks simple, right? Well, as in many cases - the devil is really in the details. Any of those three boxes is a non-trivial project in itself
Scheduler
The scheduler, or rules engine, has a bunch of if-then rules that are run every time an appropriate message from fedmsg is received. These rules can describe situations like the following examples:
- If any package is submitted for testing, run rpmlint
- If any package is submitted for stable, run depcheck and upgradepath
- If any kernel package is built, run kernel tests on all supported arches
- If an anaconda update is pushed to testing, build a new test ISO
- If a test ISO is built, run the automated installation tests against it
- If a new fedup or fedup-dracut build is submitted for testing, run automated upgrade tests on configurations X, Y and Z.
- If a package written in C is built, run static analysis against the new package
The possibilities are pretty much endless but I think that covers enough territory to get a few ideas rolling.
Task Execution
Task execution could be thought of as the center of taskbot. Once a task request comes in from the scheduler, this component is responsible for properly setting up and delegating the execution of said task.
The process by which a task is executed would depend on the exact details of the task but the general process would be:
Determine task type
1a. Provision resources, if needed
Direct the test client to clone the task's git repository
2a. Run any preparation needed
2b. Download any needed external files
Direct the test client to run the task
Report results to a results store (will be described in more detail later)
Run any needed cleanup or resource deallocation
This is a bit vague since I'm trying to encompass several divergent use cases with the same description but I plan to describe the process in more detail with later articles.
The following execution paradigms would (eventually) be supported:
- Test ISO generation
- Installation tests into a blank VM
- Cloud image spawning and testing
- Package specific tests (akin to rpmlint, upgradepath and the rest of the current PUATP suite)
- Destructive testing that could leave the system under test in a non-usable or unsafe state
Results Storage
Result storage is purposely vague because it can cover a number of things from the ResultsDB which AutoQA is currently using to other result stores that hold firehose data or something simple to hold the contents of a test ISO.
In my mind, the important thing here is that results storage isn't limited to one format or one backend. The task execution engine has its' own method for storing the task result which is much less specialized and is likely independent of the more specialized task's result.
A Proof-of-Concept System
Instead of continuing to talk about taskbot in the completely abstract sense, I've been working on a rough proof of concept system.
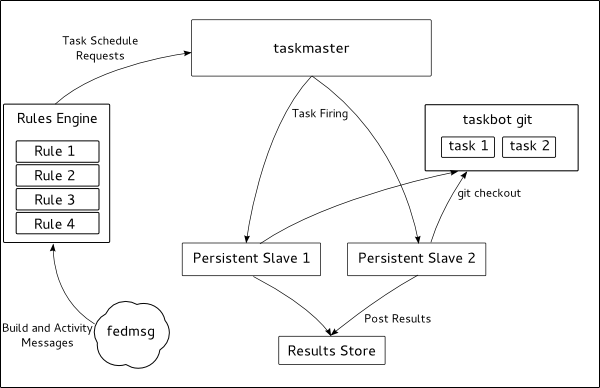
This is somewhat a rehash of the earlier diagram but is more specific on how the pieces work together as I've been implementing it so far. It isn't a representation of where I want the system to be when it's done - just a decent representation of what currently exists. Specifically, there is no support for the ephemeral task clients that I mentioned earlier but I simple and more specific visual representation of what currently exists would be useful for explanation.
Intitial Goals
I've generally found that while some planning is required to have a project end well, after a certain point the best way to find the limitations in something is to implement a proof-of-concept system. With that in mind, I'm going to be moving the proof-of-concept system I've started somewhere a bit more public than running on my personal systems behind a firewall.
What I'd like to eventually see in the proof-of-concept is the following:
Task triggering via fedmsg (working but rather hacky)
Multiple test types and examples of things which could fit into the types
Basic package-level tests ( partially done but kind of hacky)
- rpmlint is an example
Tasks Requiring VM provisioning
- basic install using infinity
Non-traditional tasks
- Test ISO builds
- Running the gcc-python-plugin against python packages with C extensions
One task per git repository, tasks cloned from repository @ run time (done)
Some form of results reporting ( about 65% done)
This proof-of-concept system so far is built using buildbot as the task execution engine, some of the simpler tests from AutoQA, a simple results storage mechanism and fedmsg-hub as the method for scheduling tests.
Next Steps
I think that the next steps are a little bit more investigation and improving the proof-of-concept system and some discussion about where all of this might go.
With few exceptions, I see the implementation details as being relatively flexible. In particular, I suspect that the choice of buildbot vs. autotest is going to be interesting - both systems have their own advantages and disadvantages and no matter what we choose, we'll need to start contributing code upstream. Neither one is going to fulfill 100% of our needs out of the box but I've found both upstream projects to be friendly and as long as we work with them as we develop code, I imagine we would be able to upstream the changes which make sense.
The choice isn't limited to just those two, beaker and (parts of) HTCondor have been suggested as alternatives. I have my reasons for suspecting that neither of those would be a good fit for taskbot but I'm happy to be wrong if I've misunderstood something.
I will write updates as I have them, feel free to comment here or on qa-devel